FIRフィルタのC言語による実装は手軽でしたが速度が出ないのが欠点でした。特にDSPの信号処理向きな特異なアーキテクチャーを生かせないのが大きな問題です。そこで今回はアセンブリ言語を使ってDSPのいい部分を引き出すようなプログラミングを考えてみます
まずは循環バッファ・アクセスから見ていきましょう。これはDSPが用意しているにもかかわらずC言語が対応していない機能の最大のものです。循環バッファは1次元の配列の先頭と末尾をソフトウェア的に接続して環としてあつかうものです。C言語で書くと以下のようになります。
data = delay( i-- );
if ( i<0 )
i=TAPS-1;
このようにデータの読み書きのたびに末端かどうかのチェックを行わなければならず、大きなオーバーヘッドを生み出してしまいます。DSPはこれをハードウェアで行うため、きわめて高速な循環バッファ・アクセスが可能です。
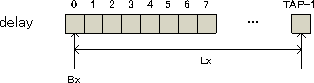
循環バッファ・アクセスをADSP-2191で実装するときにはDAGレジスタの組を正しく設定しなければなりません。レジスタの組は(Ix, Lx, Bx)からなり、同じ組のレジスタは同じ数字"x"を持っています。例えば、(I3, L3, B3)の組といった具合にします。レジスタの組を初期化する場合、LxとBxは以下の図のように初期化します。Bxには循環バッファの先頭のアドレスを設定します。図では配列delayの先頭アドレスを設定しています。Lxには循環バッファの長さを設定します。図では配列の長さであるTAPSを設定しなければなりません。
このように設定すると、Ixを使ったポストモディファイDM転送やポストモディファイPM転送によって循環アクセスを行うことができます。下にその例を示します。設定を済ますと、アクセスだけで循環バッファを作ることができることがわかります。
ax0=delay; // ディレイラインのアドレス
reg(B0)=ax0; // B0レジスタに設定
l0=TAPS; // ディレイラインの長さをL0レジスタに設定
m0=1; // 前向きにアクセス
i0=delay; // ポインタに先頭アドレスを設定
...
ax0=dm(i0+=m0); // アクセスしてポインタを進める。必要があれば循環処理
積和演算はその名のとおり二つの数の積をとってこれまでの和に足しこみます。C言語では次のプログラムのうち、sum += delay[j--]*h[i] の部分がそれです。
for ( i=0; i<TAPS; i++ ){
sum += delay[j--]*h[i];
if (j<0)
j=TAPS-1;
}
アセンブリ言語では、この部分は1命令で記述することができます。
mr = mr + mx0 * my0 (ss);
さて、アクセス部分と積和演算についてほぼ見当がつきましたので、全体を順を追って眺めてみましょう。
最初は宣言部分です。この部分ではタップ数を宣言し、さらにdelayとhを配列として宣言します。hにはインパルス応答を初期値として格納します。inとoutはテスト用の配列で、inは入力信号列、outは出力信号列です。
// フィルターのタップ数を宣言
#define TAPS 9
#define SAMPLE 20
// データセクション
.section/dm data1;
.var delay[TAPS]; // ディレイライン
.var h[TAPS]={0.8r, -0.7r, 0.6r, -0.5r, 0.4r, -0.3r, 0.2r, -0.1r, 0.0r }; // 伝達関数
.var in[SMAPLE] = {0.5r, 0,0,0,0,0,0,0,0,0}; // 入力データ列
.var out[SAMPLE]; // 出力データ列
次はメイン関数部です。この部分はプログラム実行開始後、C言語のランタイムから呼び出されます。C言語の実行環境では乗算器が整数モードなのでDIS命令を使って固定小数点数モードに変更します。次に入出力配列へのポインタを呼び出します。init_registerはFIRフィルタ用のレジスタを設定しています。
設定が終わったら「入力-FIR-出力」の作業をSAMPLE回繰り返して終わります。
.section/pm program;
.global _main;
.extern _exit;
// メイン関数
_main:
dis m_mode; // 固定小数点モード
i1=in; // 入力データ列にポインタをあわせる
i2=out; // 出力データ列にポインタを合わせる
call init_registers; // FIRフィルタのレジスタ準備
cntr=SAMPLE; // 10サンプル
do test_loop until ce;
mx0=dm(i1+=1); // 入力値取得
call fir; // FIR実行
test_loop:
dm(i2+=1)=mr1; // 出力格納
rts;
init_registersはFIRフィルタ関連のレジスタを設定します。FIRフィルタはhおよびdelayという二つの配列にアクセスしますのでここでは二つのポインタを設定しています。
前半は伝達関数用配列hを設定しています。hも循環バッファ・アクセスを使いますので、B6レジスタとL6レジスタにベース・アドレスと配列長を設定します。ポインタであるI6はベースアドレスに設定します。I6とペアを組ませるモディファイ・レジスタM6には-1を入れます。このことからhはポインタを1サンプルごとに逆進させますので、一旦配列のベースに設定したポインタを最後尾に再設定しておきます。
後半は伝達関数用配列delayを設定しています。
// FIRフィルタのレジスタ準備
init_registers:
ax0=h; // 伝達関数列の開始アドレス
reg(B6)=ax0; // ベースに設定
l6=TAPS; // 循環バッファの長さはTAPS
m5=-1; // 伝達関数は後ろ向きにアクセスする
i6=h; // ポインタに先頭アドレスを設定
modify(i6,m5); // 1サンプル戻して最後尾につける
ax0=delay; // ディレイラインのアドレス
reg(B0)=ax0; // B0レジスタに設定
l0=TAPS; // ディレイラインの長さをL0レジスタに設定
m0=1; // 前向きにアクセス
i0=delay; // ポインタに先頭アドレスを設定
rts;
さて、お待ちかねのfirルーチンです。このルーチンはinit_registerで行ったレジスタ設定をよく読んでおかないと理解できませんのでしっかり読んでおいてください。ルーチンの大まかな動きは次のようになっています:
この手続きで注意を要する点は2のストアと3の積和の関係です。FIR循環バッファを使うFIRフィルタはポインタの操作が微妙なので慎重な操作が必要です。以下のプログラムは次のような論理で組んであります。
このように、ルーチン前半のストアでdelayが最新状態に更新されています。ポイントはhをTAPS回アクセスするのに対してdelayをTAPS+1回アクセスしていることです。このため、hはfirが呼ばれるたびに毎回同じ位置からアクセスが始まるのに対して、delayは一つずつアクセス位置が前進していきます。これはサンプルを追加していくためにおきる挙動です
ルーチンから抜ける直前に丸めを行っています。これが必要な理由が直感的にわからない人が多いのですが精度を高めるには必要な作業です。DOループを終了した時点で、MRレジスタの数値には誤差はありません。これはアキュームレーターが積による誤差を生じないよう十分長く確保してあるからです。しかし、出力として16ビット値を取り出すと丸め誤差が生じます。単にMR1を取り出すと値が切り捨てになるために最大+1LSBの誤差が生じます。しかし丸めてしまえば誤差は±0.5LSBとなります。
切捨てでも丸めでもピーク・トゥー・ピークの値が1LSBなので両者の間に大きな差はないと考える人もいます。しかし雑音の影響はパワーで考えなければならないため信号の振幅を2乗して評価します。その結果、両者の差は大きなものになります。
// input : ax0
// output: mr1
fir:
mr=0; // SUM=0
dm(i0+=m0)=mx0; // 最新のサンプルをストア
cntr=TAPS; // TAPS回繰り返し
do fir_loop until ce;
mx0=dm(i0+=m0); // ディレイラインのロード(古い物から新しい物へ)
my0=dm(i6+=m5); // 伝達関数のロード(後ろから前へ)
fir_loop:
mr=mr+mx0*my0(ss); // 積和
mr=mr(rnd);
rts;
今回はアセンブリ言語で書き下しただけで、とくに最適化は行っていません。それでもループ内部は3命令になっており、1タップあたり3サイクルで実行できるようになりました。次回はこれを最適化してみましょう。
次は⇒最適化