トリプル・バッファ
EZ-KIT Lite BF533の上ではAD1836のLRチャンネルだけを取り出すことが出来ません。これはEZ-KIT lite BF533でのAD1836AとADSP-BF533の結線がTDM動作を前提にしていないためです。しかし、もし取り出すことが出来ていたら、トリプル・バッファ化が必要になっていたでしょう。
なぜならダブル・バッファには本質的な危険が存在するからです。
ダブル・バッファはなぜ危険か
ダブル・バッファは信号処理とデータ転送を同時に行ううまい方法ですが、FIFOバッファ付きのDMAシリアル・ポートを使う場合には注意が必要です。と言うのは、FIFOバッファが存在する場合には送信DMAの転送ポインタは受信DMAの転送ポインタより先を行っており、DMA完了割り込みの扱いがきわどくなるからです。
この様子を図1で説明します。DMAと処理の割り込みを受信DMA完了割り込みで取っていると仮定します。完了割り込みはバッファRx_aの終端とRx_bの終端で交互に発生します。図1aはRx_aの受信割り込みが発生した直後で、ハーフトーンに塗ったRx_aをプログラムが処理しています。このとき、送信DMAの読み込みポインタは受信DMAの書きこみポインタより先に行っています。さて、図1 bはRx_bへの受信データの転送が終わる直前の様子です。この状態でRx_aはまだソフトウェアが扱ってよいはずですが、送信DMAポインタが先に進んでいますので実はTx_aでの送信が始まっているのです。
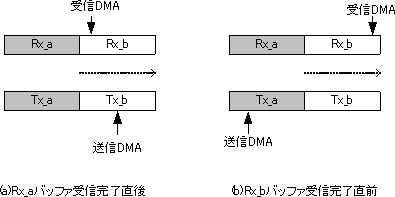
図1 DMA転送ポインタの進み具合
ADSP-BF533はDMAに16bit 4ワード、SPORTに16bit 8ワードのFIFOバッファを持っています。そのため、DMAがバッファをアクセスしているのは、実際に送信されているデータよりも12ワード前方になります。この結果、受信DMA完了割り込みで同期を取ると、送信は実際には次のバッファの12ワード目あたりをフェッチしているということになります。
AD1836 は1サンプルで32bitワード*8(16bitワード*16)の転送を行いますから、上の送受のずれは、DMAの単位を8サンプル程度にしておけばまあまあ無視できるとわかります。しかし仮にLRデータだけ転送できるとなると、送受のずれは3サンプルです。さらに、もしSPORTが32bitデータではなく16ビットだけ転送する(この方法はLSB未満がランダムになるので注意)となると、送受のずれは6サンプルになります。
このような先読みの影響を小さくしたければ、一回のDMAで転送するサンプル数を大きくしてください。たとえば48サンプル(16bitワード*96)の転送を一度に行えば、ずれは6/48=1/8=12.5%であり、CPUは全体の87.5%を信号処理に使えます。仮にそれを超えると、送信バッファへのデータ格納の一貫性に深刻な問題が発生します。
大きなバッファを使わずCPUの使用可能時間を100%に近づけたいときにはどうすればいいでしょうか。その場合はトリプルバッファを使います。
トリプル・バッファはなぜ安全か
トリプル・バッファはダブル・バッファの拡張であり、その動作はダブル・バッファを知っている人にはほとんど自明です。では、ダブル・バッファとほとんど同じなのになぜ安全なのでしょう。
図2にその動作を示します。図1 bと同様、Rx_b上でのDMA転送終了直前の様子です。図1 bではこのとき送信DMAの読み込みポインタがTx_aに入っており、ソフトウェアでのアクセスと衝突していました。図2では送信DMAの読み込みポインタはTx_cに進んでおり、Tx_aはまだ安心して使えます。このように、Rx_bの転送時間一杯をRx_aの処理に使い切ることが出来るため、結果的にCPUの使用可能時間をフルに使うことが出来るのです。
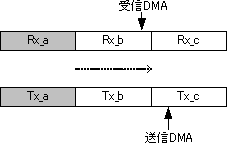
図2 トリプル・バッファ
トリプル・バッファはダブル・バッファと比べると余計なバッファが必要になります。しかし、今回論じているようにダブル・バッファでCPU利用率を上げるためにはバッファを大きくしなければならないといった特殊な場合は、トリプル・バッファのほうがメモリを節約できます。
DMAデスクリプタとトリプルバッファ
トリプル・バッファを行うにはどのようなソフトウエアを書けばよいでしょうか。TOPPERS/JSP上で動くAD1836A用に書いた制御ソフトでは、ダブル・バッファの主要部が以下のようになっています。
// プロセッサが使ってよいバッファを割り出す
bufTxIndex = ( &tDescA == *pDMA2_NEXT_DESC_PTR) ? 0 : 1;
bufRxIndex = ( &rDescA == *pDMA1_NEXT_DESC_PTR) ? 0 : 1;
このコードは動作中のDMAのレジスタの値から、ソフトウェアが使ってよいバッファを割り出しています。参照しているDMA2_NEXT_DESC_PTRはSPORT0 TX DMAエンジンのレジスタで、現在進行中のDMA転送が終わったときに次に読み込むデスクリプタのアドレスを保持しています。
原則的には上と同じような手続きでトリプル・バッファにも対応できますが、トリプル・バッファ化すると3つのうちひとつを選ぶために2つの判定のチェーンになります。これは気分が悪いのでテーブルを使った方法を考えてみました。
トリプル・バッファを使う上でDMAデスクリプタにひとつフィールドを追加することを考えましょう。もともとDMAデスクリプタはADSP-BF533のDMAエンジンが読むためのものですが、未使用の部分にデータを追加しても問題はありません。そこで、図3のように、デスクリプタの末尾にavairableフィールドを追加します。このフィールドはstartフィールド同様にバッファへのアドレスを格納します。ただし、startとは格納するバッファが異なります。
startフィールドが格納するのはそのデスクリプタに関連付けられたバッファアドレスであり、デスクリプタが読み込まれるとそのバッファでの転送が始まります。一方、avairableフィールドではそのデスクリプタの2つ前のデスクリプタと関連付けられているバッファを指し示します。なぜそのようなことをするのでしょうか。
図1を見ながら説明しましょう。この図はバッファRx_b上でDMA転送が進んでいるところを示しています。このとき、DMA_NEXT_DESC_PTRが示しているのは、転送中の次のデスクリプタですから、Desc_Cです。そして、ソフトウェアが扱ってよいバッファはDesc_Cの2つ前のデスクリプタに関連付けられたバッファと言うことになります。
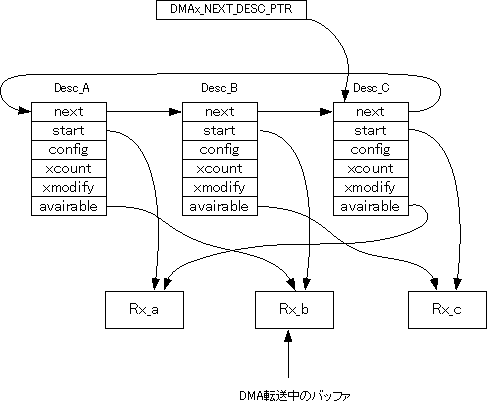
図3 トリプル・バッファの実装
このような構成の場合、プロセッサが使ってよいバッファは次のように割り出します。
// プロセッサが使ってよいバッファを割り出す
bufTxAddr = ( struct DESCRIPTOR * )( *pDMA2_NEXT_DESC_PTR) -> avairable;
bufRxAddr = ( struct DESCRIPTOR * )( *pDMA1_NEXT_DESC_PTR) -> avairable;
このほかにもう一つ方法があります。DMAx_CURR_DESC_PTRは、デスクリプタ・リンク・モードのとき、デスクリプタを読み終わると最後のエレメントの次のアドレスを指し示します。つまり、図3のようなデスクリプタを作ると、DMAx_CURR_DESC_PTRはデスクリプタを読み終えると同時にavairableを指すことになります。そこで、次のように書くこともできます(ただしavairableには2つ前ではなく1つ前のバッファのアドレスを入れておきます)。
// プロセッサが使ってよいバッファを割り出す
bufTxAddr = ( void * )( *pDMA2_NEXT_DESC_PTR);
bufRxAddr = ( void * )( *pDMA1_NEXT_DESC_PTR);
まとめ
トリプル・バッファはTX DMAが先読みを行う場合にも安全にCPU時間を使い切ることの出来る優れた方式です。ダブル・バッファに比べるとデータエリアが余計に必要になりますが、CPU時間が大事な場合にはむしろ節約になることもあります。