SPORTの送受同期
ADSP-BF533のシリアルポートは、送信と受信のコントロールレジスタが別々になっているため、両者のイネーブルを同時に行うことが出来ません。その結果、二つの部分のフレーム同期が一致しない可能性があります。以下、この問題について考えます。
なにがおきるのか
SPORTの送信と受信を行うとしましょう。フレーム付伝送であれば、マルチチャンネルでもI2Sでもかまいません。送受のフレーム構成は同じとします。また、フレーム同期信号は外部入力です。ここで次のようなプログラムを実行してSPORTの動作を開始します。
*pSPORT0_TCR1 |= TSPEN;
*pSPORT0_RCR1 |= RSPEN;
このプログラムは、極めて短い時間に実行されますが、同時ではありません。そのため、次のようなことが起きえます。
- 送信ポートがイネーブルになる
- 送信ポートがフレーム同期を獲得して転送を開始する
- 受信ポートがイネーブルになる
- 受信ポートは次のフレーム同期まで転送を開始しない
このため、受信ポートの動作は送信ポートより1サイクル遅れることになります。
このようなずれが発生する確率はどのくらいでしょうか。それはSCLKとフレームクロックの周波数比になります。システムMMRへの書き込みはSCLK周期で行われます。フレーム内部で上のような問題が発生するのはただ一箇所、二つのイネーブル書き込みがフレーム同期信号のアクティブエッジをまたぐ場合です。一方、場合の数はフレーム内部のSCLKのパルス数だけあります。したがって、周波数比がそのまま確率になります。SCLK = 133MHz, Fs=48KHzのとき、確率はおよそ2800分の1です。
この問題に関する網羅的な事例の検討は、組み合わせの数が多すぎて現実的ではありません。そこで、AD1836Aを使って8サンプルごとにDMA割り込みを起こすダブルバッファ構造を考えましょう。つまり、ソフトウェアとハードウェアの同期は8サンプルごとに行います。また、割り込みは受信ポートからかけることにします。
送信を先に開始する場合
まず、送信を先にイネーブルにする場合を考えましょう。プログラムは
*pSPORT0_TCR1 |= TSPEN;
*pSPORT0_RCR1 |= RSPEN;
のようになります。ここで正常動作時を考えましょう。正常と言うよりも、希望する動作です。この場合、送信と受信を開始したあとにフレーム同期信号がやってくるため、双方の通信が同時に始まります(図1)。
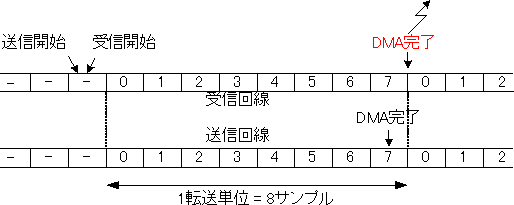
図1 正常動作時
ここで注目しなければいけないのは、送信DMAの完了位置です。ここではDMA完了とともに、オートバッファかデスクリプタ・チェインによる次のDMA転送に移る位置です。そこが、実際のデータ転送より前にあることに注意してください。SPORTは送信バッファとして32bit 4wordのFIFOを持っています。DMAはこのFIFOをいっぱいにするために、実際のデータ転送がデータ送信より4word前に終了するのです。AD1836Aの1サンプルは32bit 8wordからなるため、結局DMAは最後のサンプルの送信のちょうど真ん中で終了して次に移ることになります。
期待通り図1のように動作する場合、受信DMA完了(赤)による割込みを受けてソフトウェアとDMAの同期を取ります。この割り込みの時点で送信DMAも受信DMAも次の転送に移っているため、DMAの状態を受けての動作には何の問題もありません。
つぎに送信開始と受信開始がフレーム同期信号をまたぐ場合を考えます(図2)。
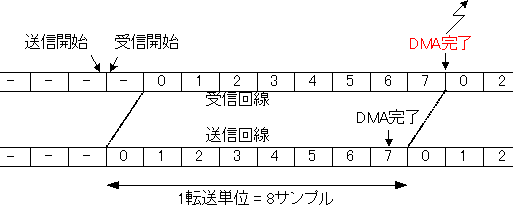
図2 送信と受信の開始位置がフレーム同期をまたぐ場合
この場合、受信開始が送信開始より1サンプル遅れます。しかし、受信DMAの完了時に送信DMAが完了していること自体には変わりありません。そのため、ソフトウェアによるダブルバッファ処理に関して特に問題は発生しません。ただし、プロセッサに与えられた時間は1サンプル分減ることに注意してください。バッファの送信が始まる時間は、バッファの受信を基準点とすると、図1の場合より1サンプル早くなります。そのため、プロセッサは1の場合より早く処理を終わらせて送信に備えなければなりません。
受信を先に開始する場合
次に受信を先に開始する場合を考えます。プログラムは
*pSPORT0_RCR1 |= RSPEN;
*pSPORT0_TCR1 |= TSPEN;
となります。この場合も、送信と受信の開始の後にフレーム同期が訪れるならば問題はありません。この場合の動作を図3にしめしますが、これは送受信の開始を除くと図1の場合と同じ時間関係になっています。
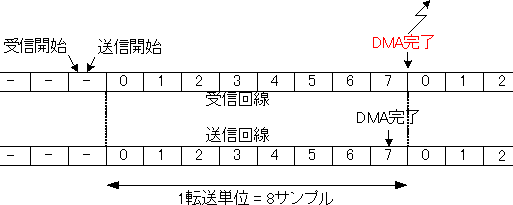
図3 正常動作時
時間関係が同じため、挙動もまったく図1の場合と同じです。この場合は何の問題も起きません。
最後に送信と受信の開始がフレーム同期をまたぐ場合を考えます(図4)。
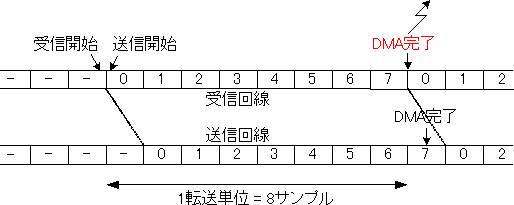
図4 送信と受信の開始位置がフレーム同期をまたぐ場合
この場合は、送信開始が受信開始より1サンプル遅れます。その結果起きることには注意が必要です。AD1836Aの場合、1サンプルが32bit 8wordからなります。そのため、最後の送信データの送信中に、DMAが転送を完了して次のブロックに進んでいました。動作が1サンプル遅れたことにより、この送信DMAの完了位置は図4に示すように受信DMAの完了より後になります。
この場合なにが起きるでしょうか。ダブルバッファ操作のための送信バッファ決定を送信DMAの状態をもとに行っているばあい、バッファの判定には致命的な誤りがおきます。受信DMA完了の時点で送信DMAは完了しておらず、その結果新しいDMA状態だとおもって取り出したものは実は古い状態だということになります。
一方、ダブルバッファ操作のための送信バッファ決定を送信DMAの状態をもとに行っているばあい、バッファの判定には何の問題もありません。この方法はやや安易であるためあまり勧められないのですが、偶然にもこの場合は正しく動きます。
以上の考察から、受信開始の後に送信開始を行うシーケンスは、好ましくないことがわかります。
プログラム内部で何がおきるか
以後、送信開始のあとに受信開始を行う場合のみ取り扱います。
これまでの考察で送信データの転送に対して受信データの転送が1サンプル分だけ遅延する場合があることがわかりました。この結果、プログラム内部で何が起きるでしょうか。
すでに述べたように送信データを作り出すのにプロセッサに与えられる時間は1サンプルだけ少なくなります。もし、性能ぎりぎりのところで動作していると、これは何か不都合を引き起こすかもしれません。しかし、性能に余裕がある場合や、DMA転送一回あたりのサンプル数が多い場合には、この変動は無視できます。
よほどクリティカルな要求がない限り、1サンプルのずれはプログラムにとって致命的な問題にはつながりません。
システムで何がおきるか
プログラムが破綻しなくても、システム全体でみるとまずいことになるかもしれません。オーディオ・アプリケーションではサンプルがずれることを嫌います。送信と受信の間の遅延量ならともかく、マルチチャンネル・オーディオにおいてチャンネル間の時間関係が場合によって異なるというのは深刻な問題です。
回避方法
私が作るような趣味のプログラムであれば、以上のサンプルのずれはまったく問題ありません。無視できます。しかし、マルチチャンネル・オーディオなどでは看過すべからざる問題です。
問題を回避するには、フレーム同期信号が来た直後に関連するSPORTを動作させるしかありません。具体的な手順は以下のとおりです。
- 受信ポートをひとつだけ動作させる。
- DMA終了割り込みを使って同期信号の直後を捉える。
- 直ちに受信ポートを停止させる。
- すべてのポートをイネーブルにする。
これですべてのポートが同時にフレーム同期を捉えて動作するようになります。